

Raspberry Pi 4 3台にSSDを取り付けまして。
分散ファイルシステムを構築してみようと思います。各ノードでOSD(Ceph Object Storage Daemons)を動かしまして、ストレージを結合します。
ストレージの容量は、1TBのスティックSSDを用意、CoreOSに64GB使用しました。残り容量、867GiBを使用した場合、3台で2.5TiBの容量をOSD用に確保できました。
OSDは、ノードを増やせば増やすほど、容量と速度が上がる動きになります。(よく使うデータは多くのノードに分散
具体的には、次の使い方になりますが、それは別の記事、後編にて。
- ブロック・ストレージ
- ファイルシステム・ストレージ
- オブジェクト・ストレージ(S3・Swift)
- NFS・ストレージ
まずは、OSD構築までの手順を記録させて頂こうと思います。
Raspberry Pi 4 + Fecora CoreOS + Kubernetes + Rook Ceph OSD構築手順
使用する機材
Raspberry Pi 4を(最低限)3台と、SSDを3つ、電源とスイッチングハブと配線になります。
詳細はこちらの記事になります。
[amazonjs asin=”B08N4JHGJL” locale=”JP” title=”【Amazon.co.jp限定】バッファロー SSD 外付け 1.0TB 超小型 コンパクト ポータブル PS5/PS4対応(メーカー動作確認済) USB3.2Gen1 ブラック SSD-PUT1.0U3-B/N”]
容量1TBのSSDを、ノード3台で使用したところ、2.5TiBのOSDクラスタを構築できました。今後、SSDの容量あたりの単価は下がると思われますので、同じ価格で更に大きなOSDクラスタを構築できるようになると思います。
今回作成する分散ファイルシステムは、スケールアップ(各ノードにSSDを追加・交換)も可能ですが、スケールアウト~ノードを足して、容量を増やすことも可能です。クラウドネイティブ。無駄がない感じがします。(性能不明
OSはFedora CoreOSを使用させて頂きました
実は、arm64でクラスタを使用する場合、OSはUbuntuが基本のようです。
フットプリントの軽さから、私はFedora CoreOSでクラスタを構築して、色々と実験させて頂こうと考えていました。
分散ファイルシステムにつきましては、Fedora CoreOSで構築した先人の知恵を拝借致しまして、うまく作れそうな状況です。(まだ最後まで行っていないですが
Butane/Ignitionを使用したFedora CoreOSのプロビジョニングはこちらの記事になります。node1, node2, node3の3つのホスト名/IPアドレスを割り当てる、config.ign(Ignitionファイル)を作成し、SSDブートメディアを作成して起動しました。
今回、そのSSDブートメディアのパーティション/dev/sda5を、OSD用に使用しています。
Fedora CoreOSはLVMは使用できないため注意
[blogcard url=”https://github.com/coreos/ignition/issues/1289″]
OSDクラスタを構築する手段の一つとして、LVMパーティションを使用する事が可能ですが。Fedora CoreOSでは、LVMは使用できないため、注意が必要です。
ネットワーク経由で外部マシンのLVMパーティションを、OSDに組み込みたい、という要件が無ければ、私はとくに問題はないかなと考えています。
今回のように、各ノードのストレージを使用する場合は、LVMはなくても大丈夫だと思います。(本当?未検証
Kubernetesクラスタ構築
分散ファイルシステムの構築は、Kubernetesを使用させて頂きました。
Kubernetesを使用しなくても、Cephファイルシステムで構築できるのかもしれませんが。Cloud Native環境を使用させて頂くことで、構築の手間が大きく変わると思います。
今回のOSDクラスタを構築するために、私はKubernetesクラスタを10回くらい作り直しました。OSDの構築に失敗(設定ミス)すると、クラスタが暴走してフリーズします。
Kubernetesの構築は、Ansible/kubesprayを使用させて頂きました。Ansibleによるクラスタ構築は、コマンドが2つ。リセットコマンドが13分ほど、クラスタ構築コマンドが1時間16分ほどで完了します。
リセットはKubernetesの削除になります。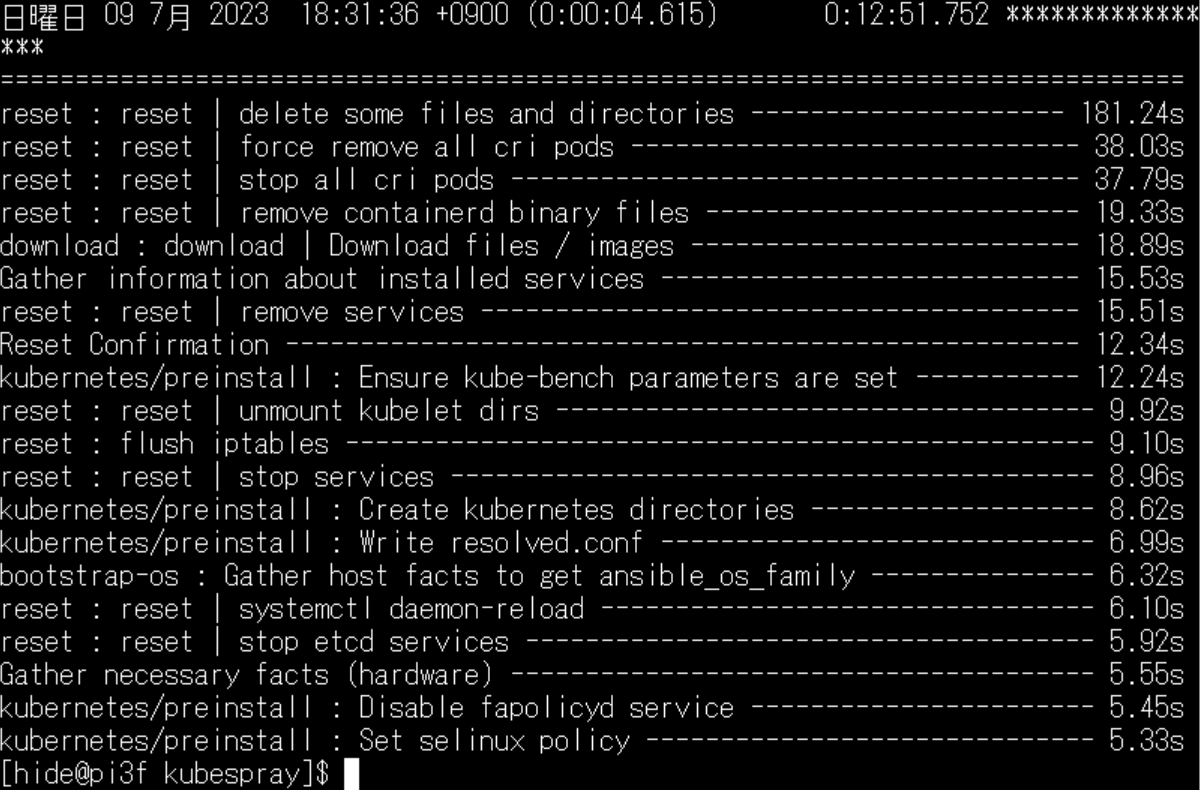 再構築は1時間半ほど。
再構築は1時間半ほど。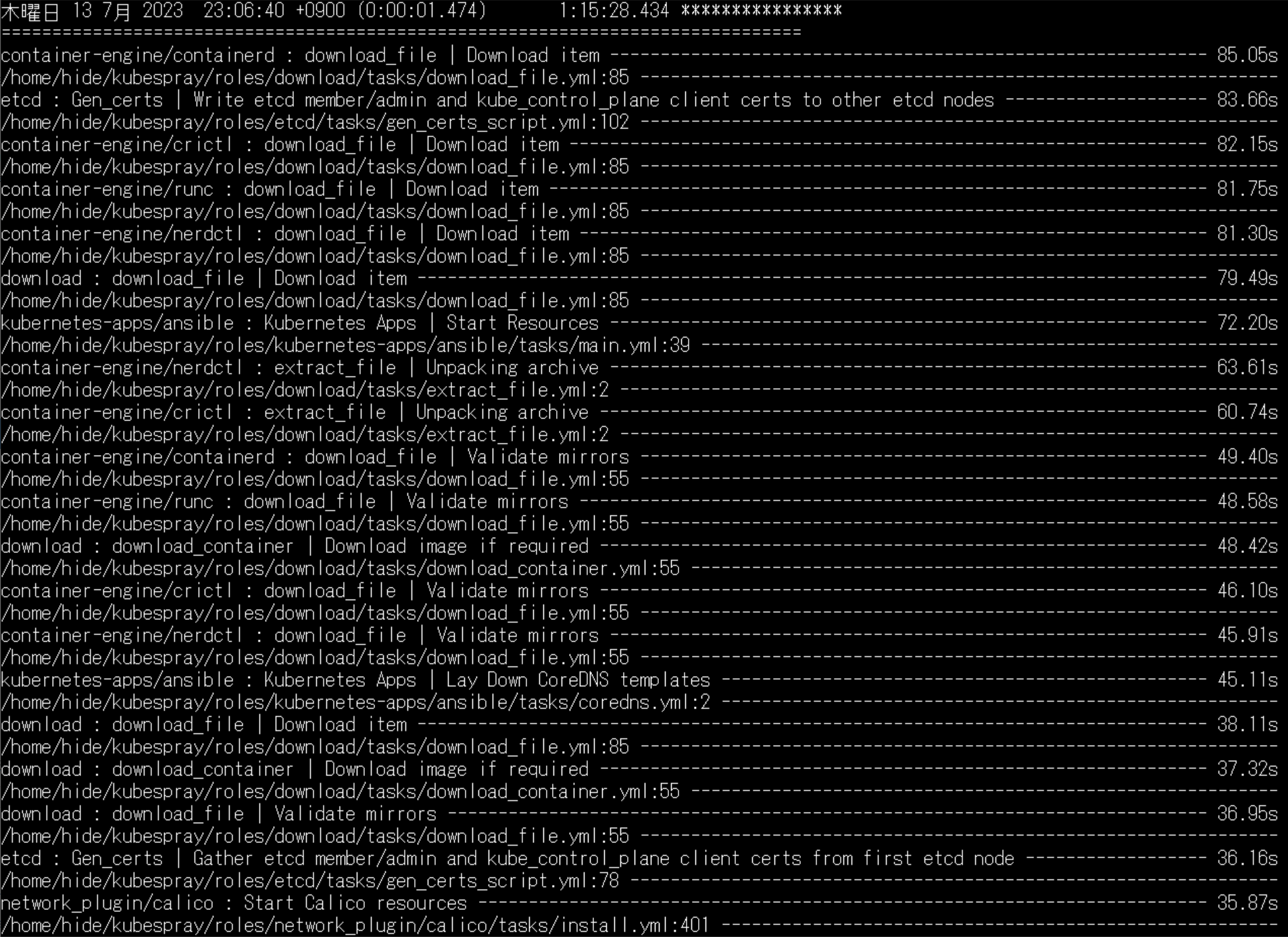
基本的に、のんびり待っていればKubernetes環境が作れてしまいます。
こちらの記事で、そのようなコマンド2つでクラスタ構築が可能です。
ファイル・ディスクリプタの調整
Fedora CoreOSでrook ceph OSDクラスタを構築する場合、ファイル・ディスクリプタの制限を外しておく必要がある、という情報を拝見しました。
[blogcard url=”https://github.com/coreos/fedora-coreos-tracker/issues/329″]
Butane/Ignition作成の記事でも記載させて頂きましたが、各ノードにて/etc/systemd/system/containerd.service.d/override.confファイルを作成して、制限を解除しておきましょう。
cat << EOF | sudo tee /etc/systemd/system/containerd.service.d/override.conf
[Service]
LimitNOFILE=1048576
EOF
cat /etc/systemd/system/containerd.service.d/override.conf
sudo systemctl daemon-reload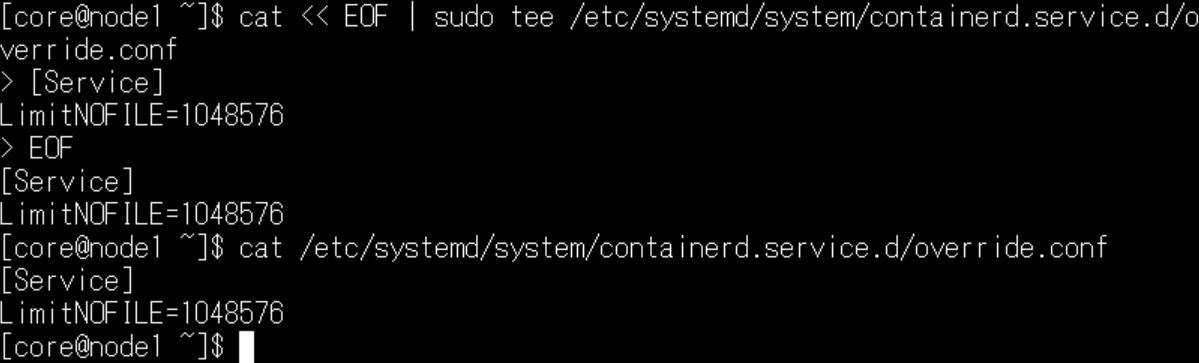
Kubernetesクラスタの動作確認
コントロールプレーンにてkubectlコマンドを実行して、すべてのノードのステータスが「Ready」になったことを確認しておきましょう。
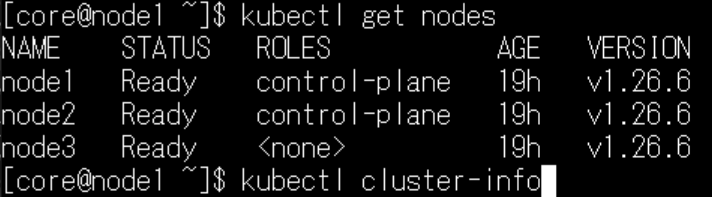
OSD構築手順
さて。本格的に、OSDの構築に入りましょう。
分散ファイルシステム用のSSDパーティションの準備
Kubernetesクラスタのノード(ホスト)に、ストレージを接続して、分散ファイルシステムを構築するわけですが。
Raspberry Pi 4に、スティックSSDを接続して運用する+Fedora CoreOSを使用するという要件から、今回は/dev/sda5パーティションを、分散ストレージに使用します。
他のブロックデバイスを使用する場合は、/dev/sda5を読み替えてください。
ちなみに、GPTパーティションのため/dev/sda5は正しく動作します。MBR系のツール(fdisk等)は使用しないほうが良いと思います。gdisk等のGPT系ツールを使用しましょう。
パーティションのファイルシステムをワイプ・ラベル削除
各ノードの/dev/sda5パーティションをOSDに認識させるため、ファイルシステムのワイプ(消去)とラベルの削除を行っておきました。
#各ノードで実行
sudo wipefs -a -f /dev/sda5
sudo dd if=/dev/zero of=/dev/sda5 bs=1M count=100
sudo gdisk /dev/sda
# c→5→エンター→p→w→yes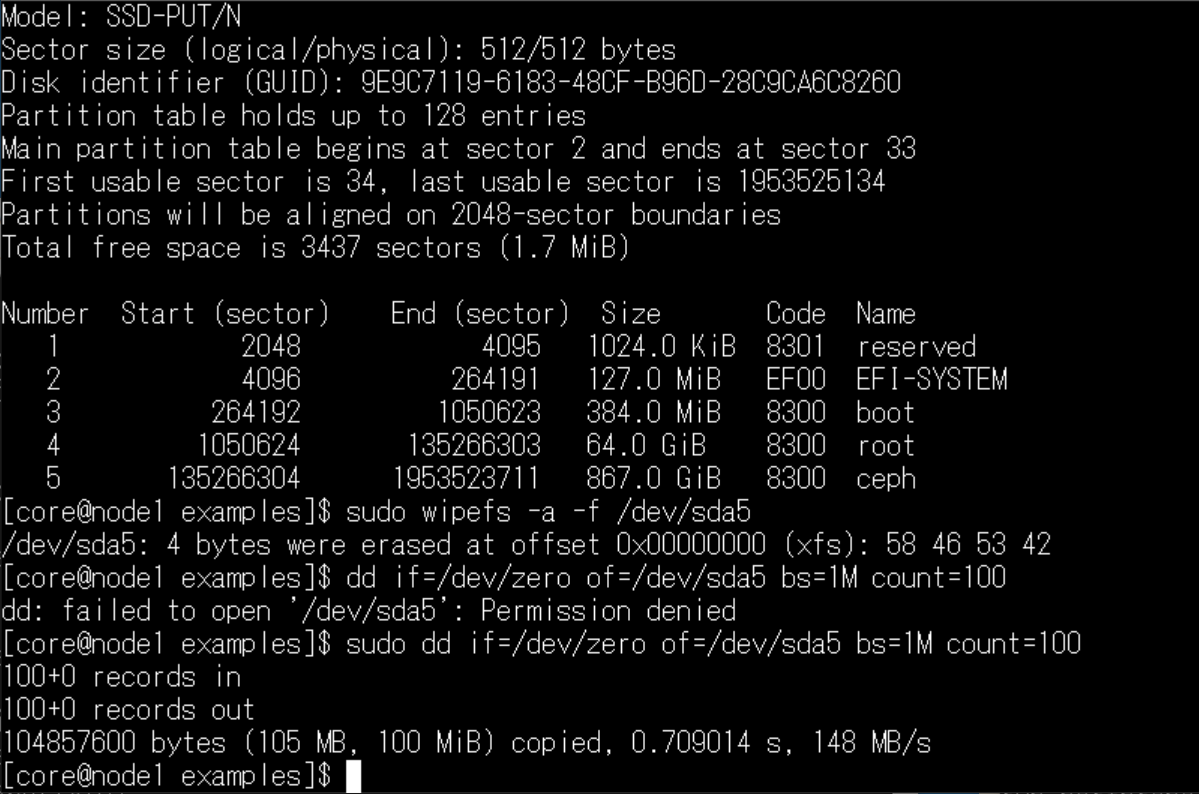 ラベルを削除する理由ですが。
ラベルを削除する理由ですが。
ラベルを検索してファイルシステムをマウントするようなアプリがあるためです。パーティションがロックしてしまい、動作しなくなるリスクを防ぐためになります。
OSDに使用するすべてのノードのパーティションをワイプ・ラベル削除しましたら、ストレージは準備完了です。
/var/lib/rook削除
# すべてのノードで実行
sudo rm -fr /var/lib/rookCephクラスタを作り直す場合、/var/lib/rookに古い情報が残っていると、再作成に失敗するようです。必ず消しておきます。
Rook Operatorのデプロイ
公式情報はこちらになります。基本的に、こちらの手順で進めます。
[blogcard url=”https://rook.io/docs/rook/v1.11/Getting-Started/quickstart/”]
まずは、rook.gitをクローンさせて頂きました。
git clone --single-branch --branch v1.11.9 https://github.com/rook/rook.git
cd rook/deploy/examples続いてRook Operatorをデプロイします。
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
# STATUSがRunningに変わるまで待ちます
# 待っている間、cluster.yamlファイルを作成しましょう
kubectl -n rook-ceph get pod
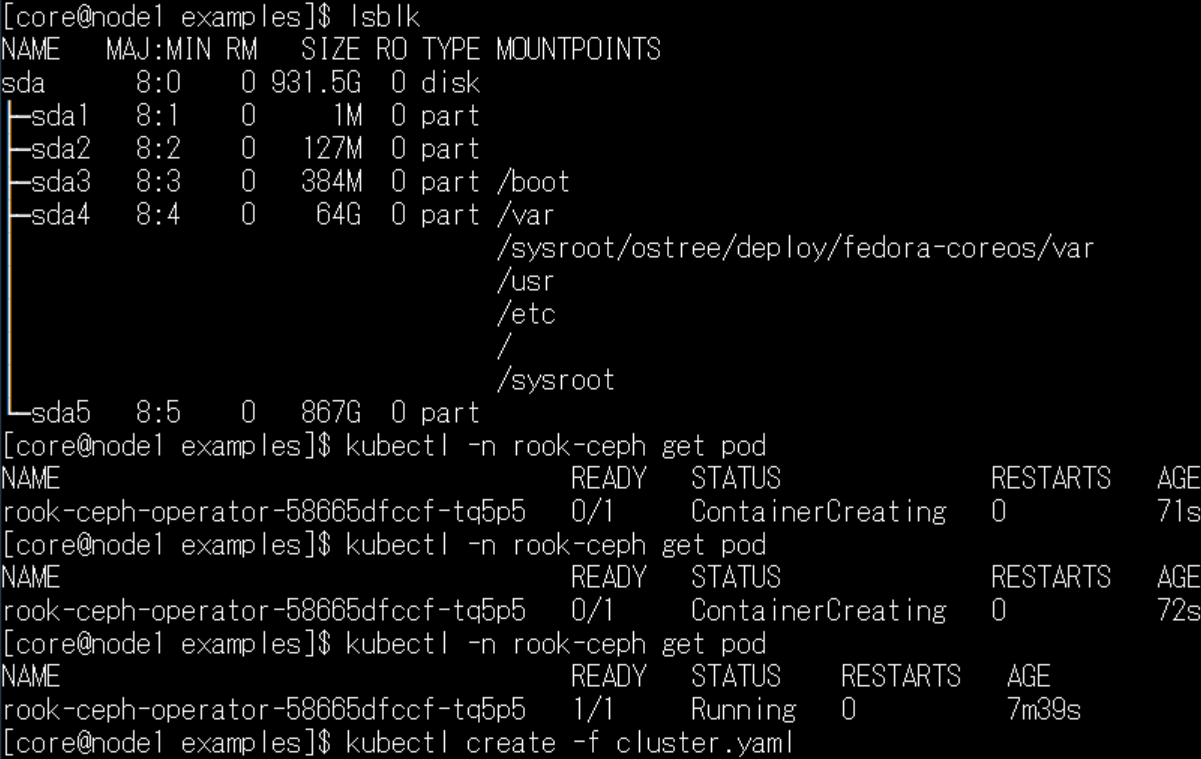 このような感じで、私のおうち環境では、7分くらいでステータスが変わりました。
このような感じで、私のおうち環境では、7分くらいでステータスが変わりました。
ちなみに、待っている間に、cluster.yamlファイルを作成してしまいましょう。
# クラスタ関係コマンド覚書
kubectl get ns
kubectl -n rook-ceph get deployments
kubectl -n rook-ceph get pod
 この段階では、デプロイメント1つに対して、ポッドが1つ動いている、という認識をしていますが。(クラスタ初心者
この段階では、デプロイメント1つに対して、ポッドが1つ動いている、という認識をしていますが。(クラスタ初心者
続いて、Ceph Clusterの構築に入ります。
Ceph Clusterの構築
各ノードのホスト名の確認
kubectl get nodes --show-labels Cephクラスタをノードごとに設定するにあたり、正確なホスト名を知る必要があります。
Cephクラスタをノードごとに設定するにあたり、正確なホスト名を知る必要があります。
具体的には「kubernetes.io/hostname」ラベルを調べる必要があります。上記のコマンドで、各ノードのホスト名を確認しておきましょう。
cluster.yamlファイル作成
この記事で作成するCeph Clusterは、通常のデフォルトから、次の2点を変更しました。
- 各ノードごとにストレージを管理できるように、nodesセクション追加
- デバイスセクションに、sda5を追加
-
useAllNodesとuseAllDevicesはfalseに変更
クラスタが不調になった原因は、このcluster.yamlファイルの作成ミスのためです。YAMLファイルということで、インデント(行の最初の空白)の数が異なると、変数の意味が変わってしまうため、注意が必要です。
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
spec:
cephVersion:
image: quay.io/ceph/ceph:v17.2.6
allowUnsupported: false
dataDirHostPath: /var/lib/rook
skipUpgradeChecks: false
continueUpgradeAfterChecksEvenIfNotHealthy: false
waitTimeoutForHealthyOSDInMinutes: 10
mon:
count: 3
allowMultiplePerNode: false
mgr:
count: 2
allowMultiplePerNode: false
modules:
- name: pg_autoscaler
enabled: true
dashboard:
enabled: true
ssl: true
monitoring:
enabled: false
metricsDisabled: false
network:
connections:
encryption:
enabled: false
compression:
enabled: false
requireMsgr2: false
crashCollector:
disable: false
logCollector:
enabled: true
cleanupPolicy:
confirmation: ""
sanitizeDisks:
method: quick
dataSource: zero
iteration: 1
allowUninstallWithVolumes: false
annotations:
labels:
resources:
removeOSDsIfOutAndSafeToRemove: false
priorityClassNames:
mon: system-node-critical
osd: system-node-critical
mgr: system-cluster-critical
useAllNodes: false
useAllDevices: false
config:
nodes:
- name: "node1"
devices:
- name: "sda5"
- name: "node2"
devices:
- name: "sda5"
- name: "node3"
devices:
- name: "sda5"
onlyApplyOSDPlacement: false
disruptionManagement:
managePodBudgets: true
osdMaintenanceTimeout: 30
pgHealthCheckTimeout: 0
healthCheck:
daemonHealth:
mon:
disabled: false
interval: 45s
osd:
disabled: false
interval: 60s
status:
disabled: false
interval: 60s
livenessProbe:
mon:
disabled: false
mgr:
disabled: false
osd:
disabled: false
startupProbe:
mon:
disabled: false
mgr:
disabled: false
osd:
disabled: falsecluster.yamlからCeph Clusterを作成
Ceph Clusterを作成する前に、Rook Operatorの作成が完了したかどうか確認しましょう。
# STATUSがRunningに変わるまで待ちます
kubectl -n rook-ceph get podそれと、もう1点、重ねて申し上げますが。
cluster.yamlファイルが誤っている場合、クラスタ全体の動作が不安定になります。
もしもクラスタを運用している場合は、podや環境設定のバックアップをお勧めします。
最悪の場合、クラスタ環境を作り直す覚悟を決めてから、実行したほうが良いと思います。
Ceph ClusterとRook Operatorをデリートすればよいのでは?と思うかもしれませんが。デリートコマンドが丸一日帰って来ないなど。ええ、消せませんでした。(環境を10回くらい作り直した
覚悟ができたうえで、Ceph Clusterを作成します。
kubectl create -f cluster.yaml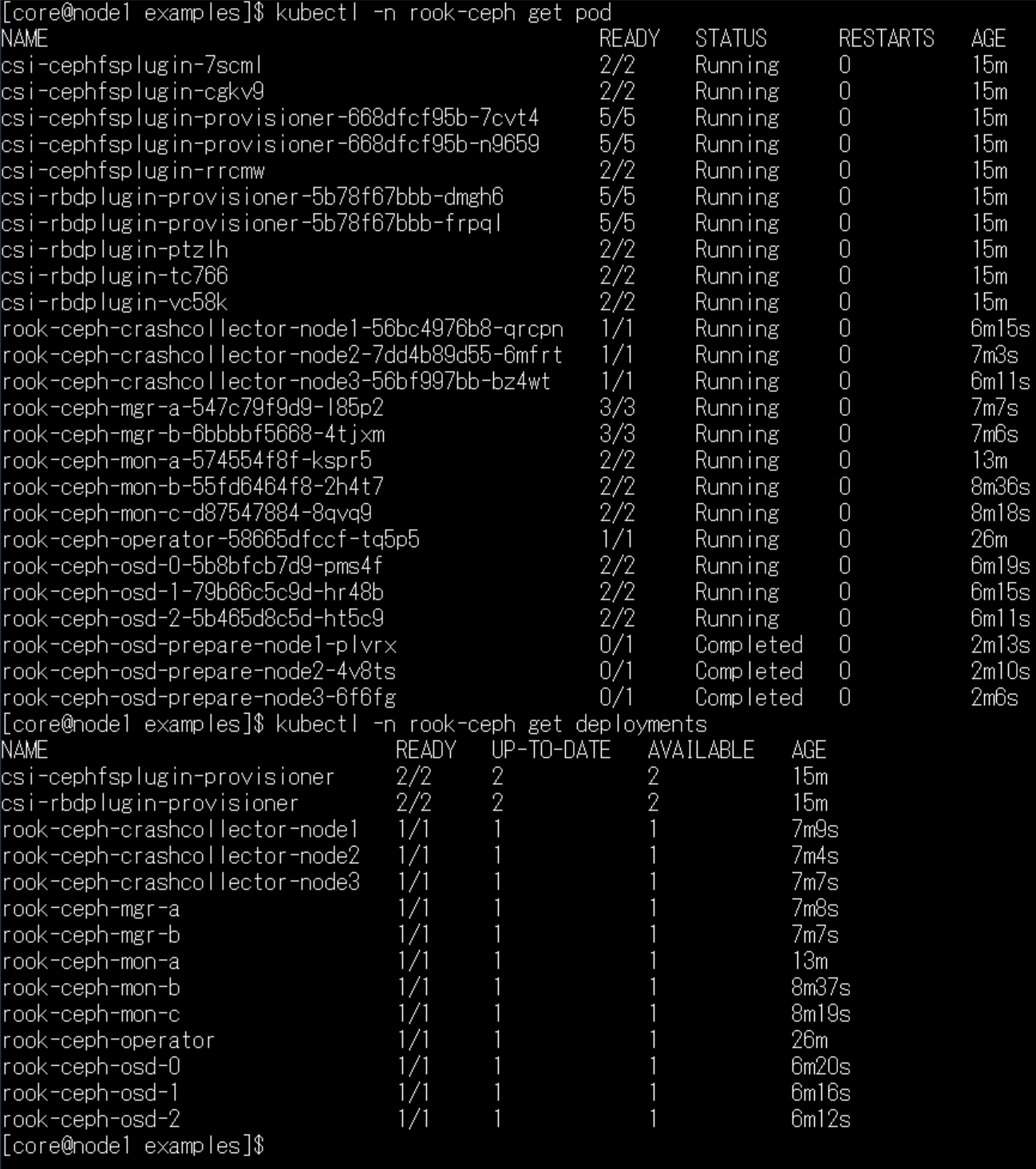 Cephクラスタの作成は、15分くらい待ちました。
Cephクラスタの作成は、15分くらい待ちました。
正しくクラスタが作成された場合、上記の画面のように、25個くらいのポッドが起動します。またデプロイメントも、mgrやmon等が、cluster.yamlで指定した個数起動します。
一方、たとえばパーティションが正しく認識されず、クラスタの起動に失敗した場合は、ポッドの数と、デプロイメントの数は少なくなります。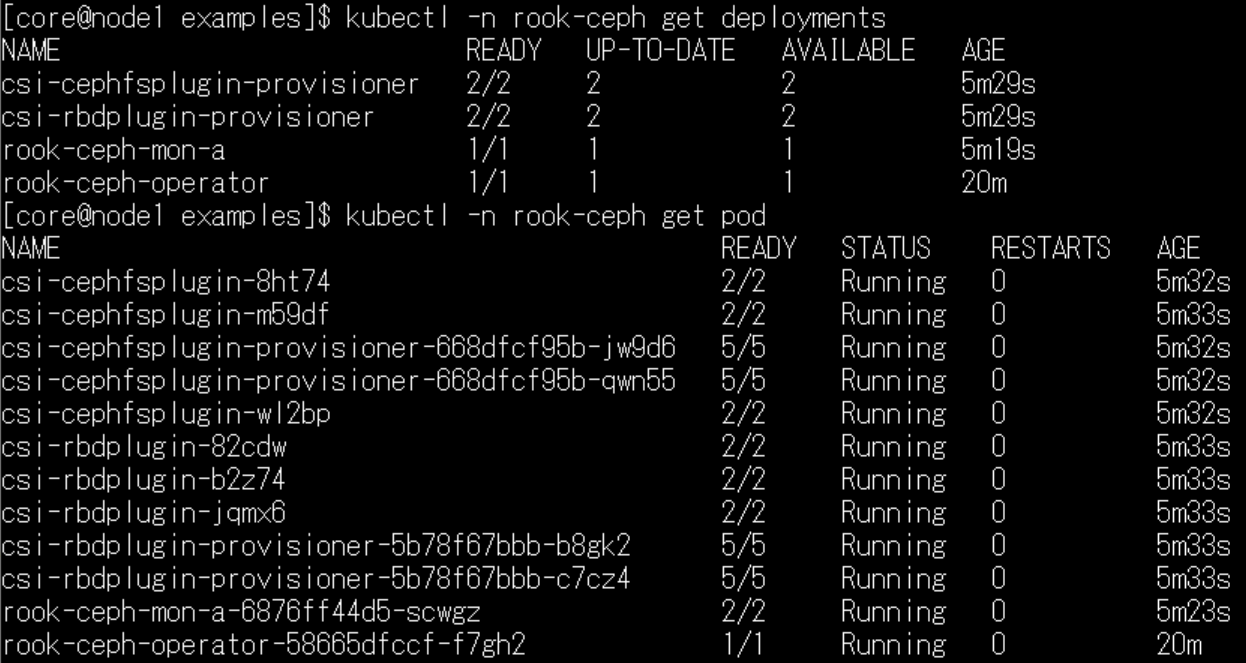 こちらは失敗例です。mgrが起動せず、ポッドの個数は半分の12個ほどです。
こちらは失敗例です。mgrが起動せず、ポッドの個数は半分の12個ほどです。
30分ほど待って、このような状況の場合は、CephクラスタとRook Operatorを削除して、作り直したほうが良いと思います。(待ち時間は環境によります
Cephクラスタの動作確認
Rook Toolboxを使用して、Cephクラスタの状態を確認します。
すべてのPodのSTATUSがRunningに変わってから実行してください。
[blogcard url=”https://rook.io/docs/rook/v1.11/Troubleshooting/ceph-toolbox/”]
kubectl create -f toolbox.yaml
kubectl -n rook-ceph rollout status deploy/rook-ceph-tools
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
ceph status
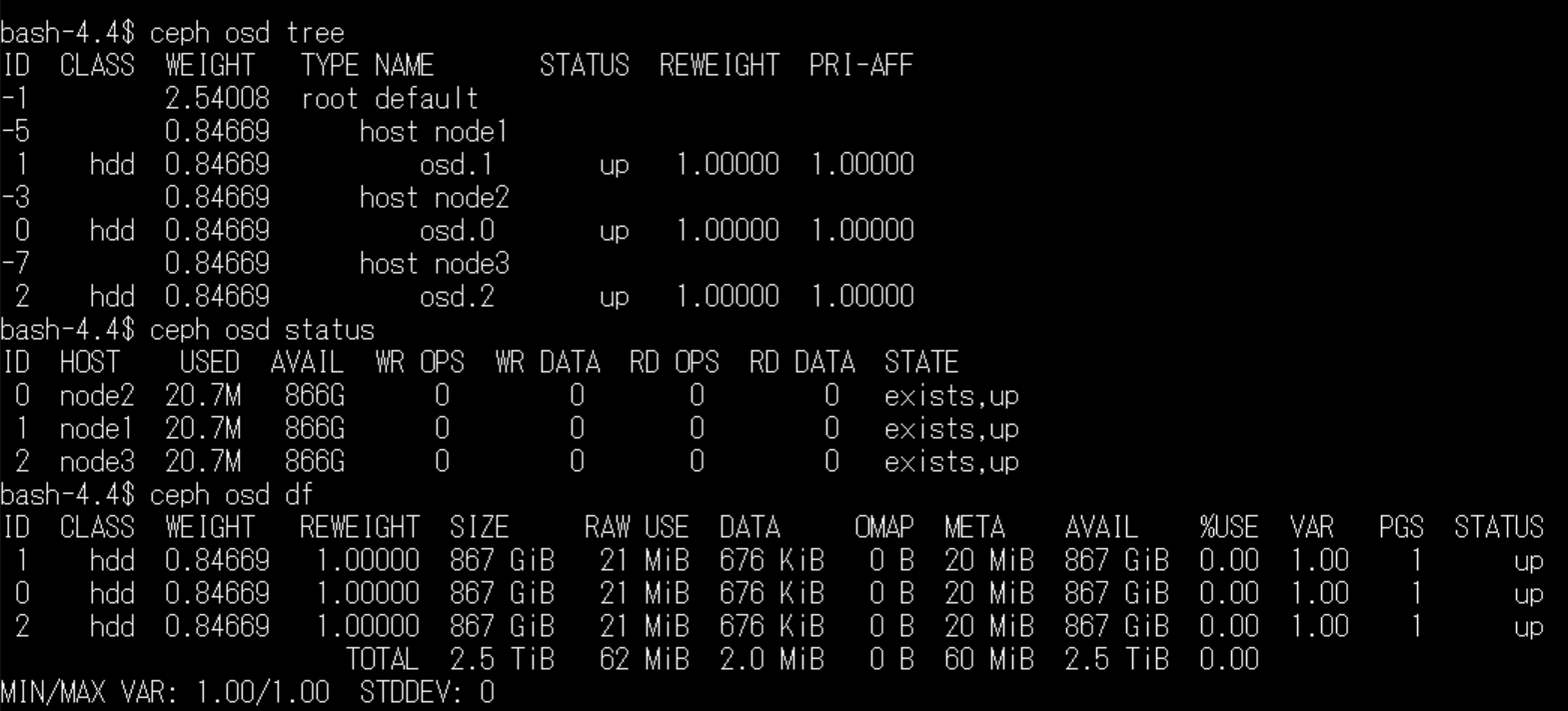
ceph osd status
ceph df
rados df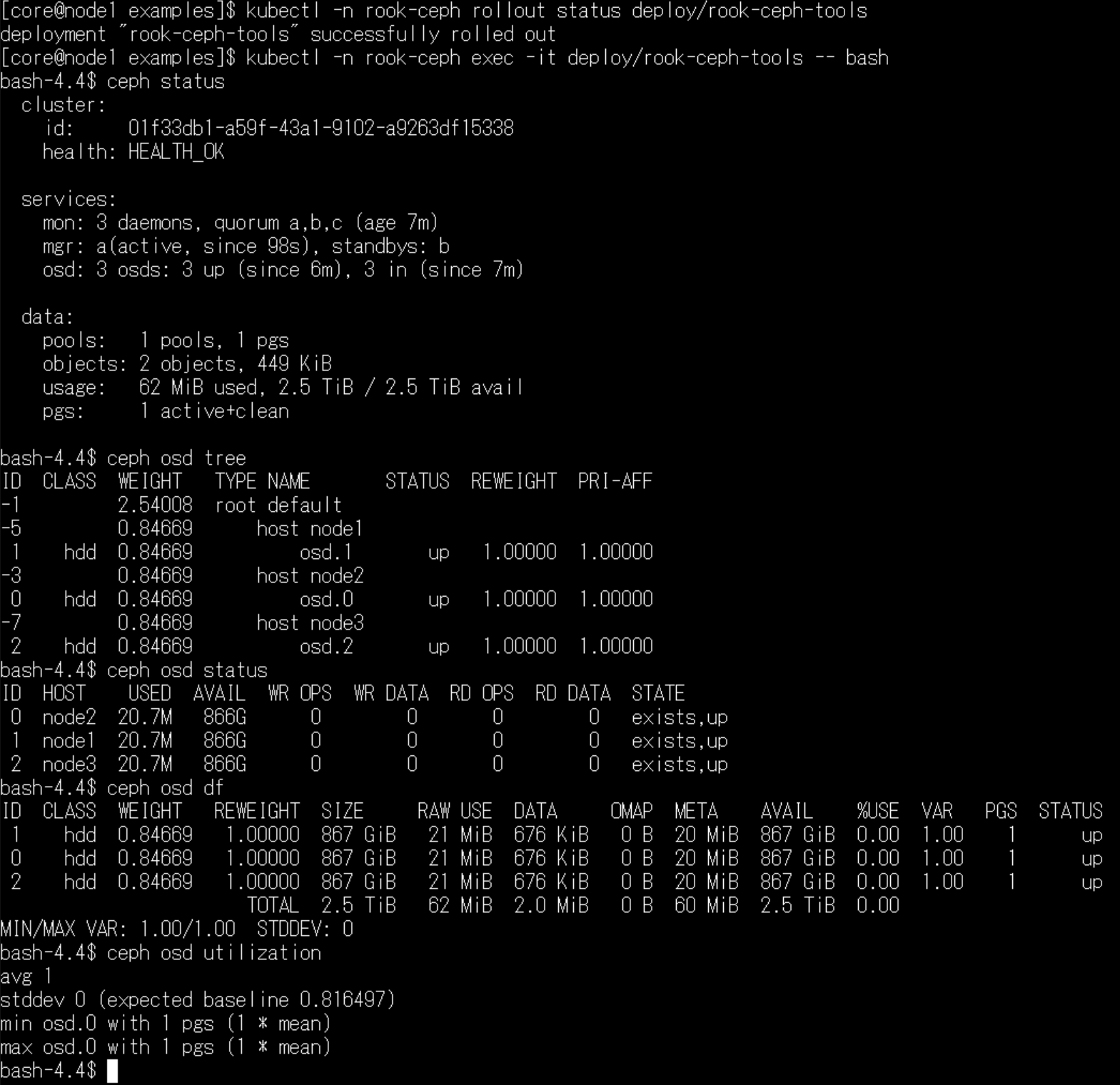
ストレージが正しく認識されていれば、このような感じで、個々のOSDの容量と、全体の容量を確認することが可能です。
toolboxの使用が終わったら、削除しておきましょう。
kubectl -n rook-ceph delete deploy/rook-ceph-tools
以上でOSDの構築が完了しました。
記事にすると、さらっと作った感がありますが。
cluster.yamlを作り直したり、Fedora CoreOS特有の問題を調べたりなど、作成はかなり苦労しました。
いちばん大変な部分は、Cephクラスタの作成に失敗すると、deleteで消せない状況かと思います。
幸い、クラスタは本格運用しておらず、削除しても問題がなかったことと、Kubesprayで構築したため、再構築が容易でした。
かなり躓きましたが、比較的短時間でOSDを構築することができました。
さて。次は、構築したOSDを、どう使うが問題になります。
それではまた次回。ごきげんよう![amazonjs asin=”4297123193″ locale=”JP” title=”目で見て体験! Kubernetesのしくみ —— Lチカでわかるクラスタオーケストレーション”]
コメントを残す