
Jetson Nanoに接続したRaspberry PiカメラモジュールV2で、YOLOv4学習済みモデルによるオブジェクト検出を実行してみました。
ビルド手順等を記録しておこうと思います。
目次
darknetのビルド手順
Jetson Nanoの初期設定
Jetson Nanoの初期設定は、こちらの記事になります。記事にも記載しましたが、microSDカードは必ずUHS-I U3 A2対応を使用しましょう。体感速度がかなり変わりますし、オブジェクト検出の性能にも影響するかと思います。
Raspberry PiカメラモジュールV2を接続
画像ファイルや動画ファイルでオブジェクト検出を行うことも可能ですが。
映像のオブジェクト検出をリアルタイムで行えるようにカメラを接続しました。
ちなみに、最近発売されたHQカメラも試してみたのですが、残念ながら接続できませんでした。この記事はRaspberry PiカメラモジュールV2で撮影した画像が掲載されています。
darknetのビルド
YOLOv4はこちらのページを参考にさせて頂きました。
こちらのページからdarknetをダウンロードしてビルドします。
- 後で使用するライブラリをインストールしておきます。
sudo apt-get install libcanberra-gtk-module -y - ソースコードを取得します。
git clone https://github.com/AlexeyAB/darknet
- darknetディレクトリのMakefileを編集します。
cd darknet vi Makefile - 1~4行目と、64行目のNVCC行を変更しました。
GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1 # 64行目付近 NVCC=/usr/local/cuda/bin/nvcc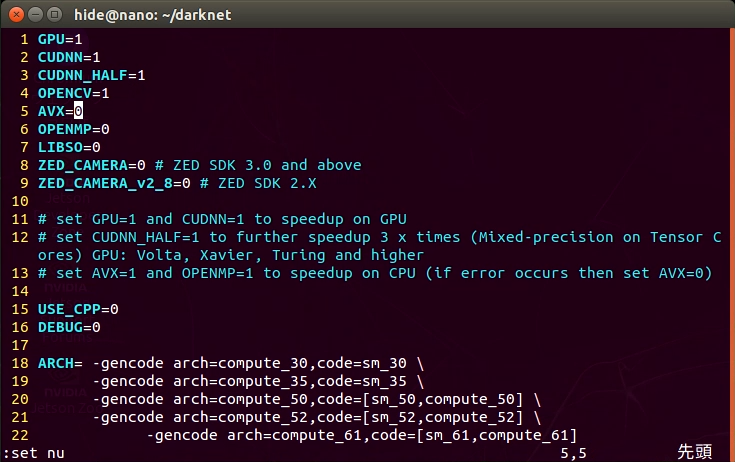
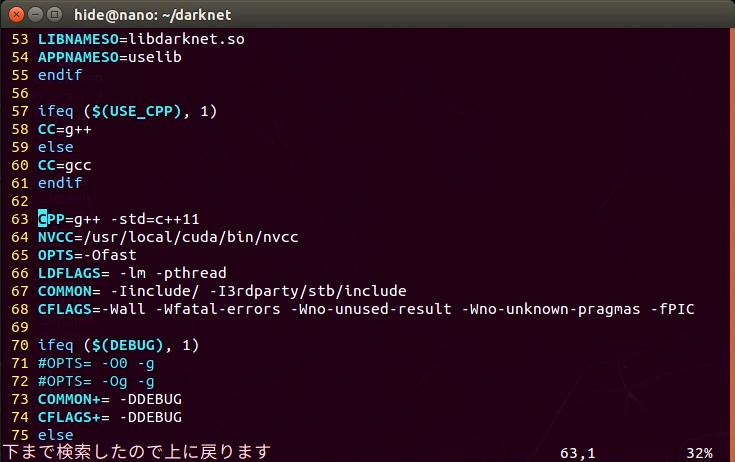
- makeコマンドでビルドします。
make
しばらく待っているとコンパイル・リンクが終わり、実行可能なdarknetが生成されます。
YOLOv3の動作確認
YOLOv4を動かす前に。dataディレクトリの中にある画像ファイルを使って、YOLOv3でオブジェクト検出しようと思います。
学習済みモデル(weightsファイル)を取得しますが、Jetson Nanoで動かしたいため、tiny版を使用しました。
wget https://pjreddie.com/media/files/yolov3-tiny.weights設定(cfgファイル)はgit cloneで取得済みのものを使用しました。
dataディレクトリのdog.jpg画像でオブジェクト検出してみました。
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg画面に正常に検出結果が表示されましたでしょうか?
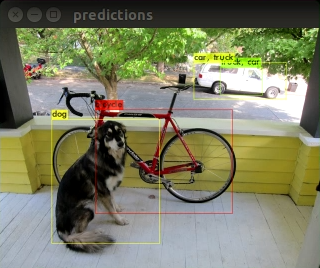
YOLOv3の結果とYOLOv4の結果がどのように違うのでしょうか?
そのあたりの細かい比較が気になる場合、dataディレクトリ内の他の画像を認識してみることをお勧め致します。
YOLOv4でリアルタイム・オブジェクト検出
次にYOLOv4でオブジェクト検出をしてみようと思います。
先ほどと同じく学習済みモデルを取得します。うまく動作しなかったため、設定も別途取得しました。
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny.cfg
v3との比較のため、dog.jpgで実行してみました。
./darknet detect yolov4-tiny.cfg yolov4-tiny.weights data/dog.jpg
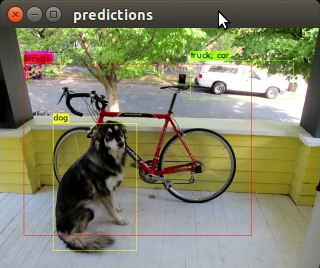
ふむふむ。枠の範囲が、v4のほうがv3よりも正確な感じがします。v3と違い、自動車が1台として認識されています。ふむふむ。
次にJetson Nanoに接続したRaspberry PiカメラモジュールV2を入力として、YOLOv4でオブジェクト検出をしようと思います。次のコマンドになります。
./darknet detector demo cfg/coco.data yolov4-tiny.cfg yolov4-tiny.weights 'nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1920, height=1080, format=(string)NV12, framerate=(fraction)30/1 ! nvtee ! nvvidconv flip-method=2 ! video/x-raw, width=(int)1280, height=(int)720, format=(string)BGRx ! videoconvert ! appsink'ふむふむ。
シャープペンシルがナイフになっていますが、オブジェクトとして認識される枠の大きさが、v3よりもずいぶん正確になった印象です。
手元のものをざっと映した感じですが、いろいろとカメラで映してみて、検出精度を確かめてみなければですね。
以上のように、Jetson Nanoに接続したRaspberry PiカメラモジュールV2で、YOLOv4学習済みモデルによるオブジェクト検出を行なってみました。
Yolo v3と比較すると、確かにオブジェクトの枠の範囲や精度が向上しているようです。
とりあえずざっと動かした感じですが、darknetのビルドオプションはまだまだ調整の余地がありそうです。Tegra向けの最適化オプションで、性能向上も望めそうです。
宜しければ色々と撮影して試してみてくださいませ。